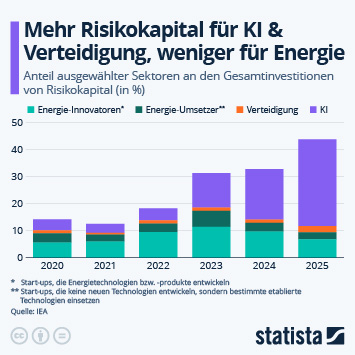
Neben der Ankündigung neuer Hardwareprodukte stand die gestrige Entwickler:innenkonferenz Google I/O im Zeichen der Künstlichen Intelligenz. Bard, das Konkurrenzprodukt zu OpenAIs ChatGPT, soll ab sofort in 180 Ländern verfügbar sein, wichtige Google-Dienste wie Fotos, Gmail, Maps und die Suche erhalten in naher Zukunft umfassende KI-Features. Die zugrundeliegenden large language models (LLM) setzen Wörter und Phrasen, im Fachjargon Tokens genannt, ohne eigenes Bewusstsein nach den wahrscheinlichsten Kombinationsmöglichkeiten zusammen. Wie diese trainiert werden, darüber schweigen sich die meisten Firmen aus – mit Ausnahmen.
Obwohl beispielsweise nicht im Detail bekannt ist, welche Ressourcen explizit zum Training von GPT-4 benutzt wurden, ist dokumentiert, dass Googles T5-Modell und LLaMA von Facebook unter anderem auf den von Google erstellten C4-Korpus zurückgegriffen hat. Dabei handelt es sich um eine Sammlung von 15 Millionen Schnappschüssen von Internetseiten auf Basis des 2019 gestarteten Common-Crawl-Projekts, die im Nachgang durch Google-Filter bereinigt wurden. Wie unsere Grafik aus Basis einer exklusiven Recherche der Washington Post zeigt, stammt rund die Hälfte der kategorisierbaren Tokens aus vier Kategorien.
Die am häufigsten vertretene ist dabei Wirtschaft & Industrie. Darin sind unter anderem Seiten wie kickstarter.com, das Portal der US-amerikanischen Börsenaufsichtsbehörde Securities & Exchange Commission sec.gov oder die Anlageberatung fool.com enthalten. Platz zwei und drei werden vom Sektor Technologie mit Seiten wie medium.com oder forums.macrumors.com sowie der Kategorie Nachrichten & Medien, die unter anderem die Internetauftritte der New York Times und des britischen Guardian sowie den E-Book-Abodienst scribd.com und die englischsprachige Wikipedia enthalten, belegt.
Die von der Washington Post ausgewerteten Daten weisen allerdings Lücken auf, da rund ein Drittel der im Korpus aufgeführten Seiten nicht kategorisiert werden konnten oder nicht mehr online sind. Außerdem spiegelt der C4-Korpus nur einen Teil der Trainingsdaten wider, kein KI-Modell verlässt sich diesbezüglich nur auf eine einzige Quelle. Die Datengrundlage für das Training von KI-Chatbots hat in Deutschland auch Datenschützer:innen auf den Plan gerufen. Anfang April gab die Taskforce KI der Datenschutzkonferenz bekannt, ChatGPT auf die Einhaltung der DSGVO und der Verarbeitung personenbezogener Daten abklopfen zu wollen.